George Reitsma Question
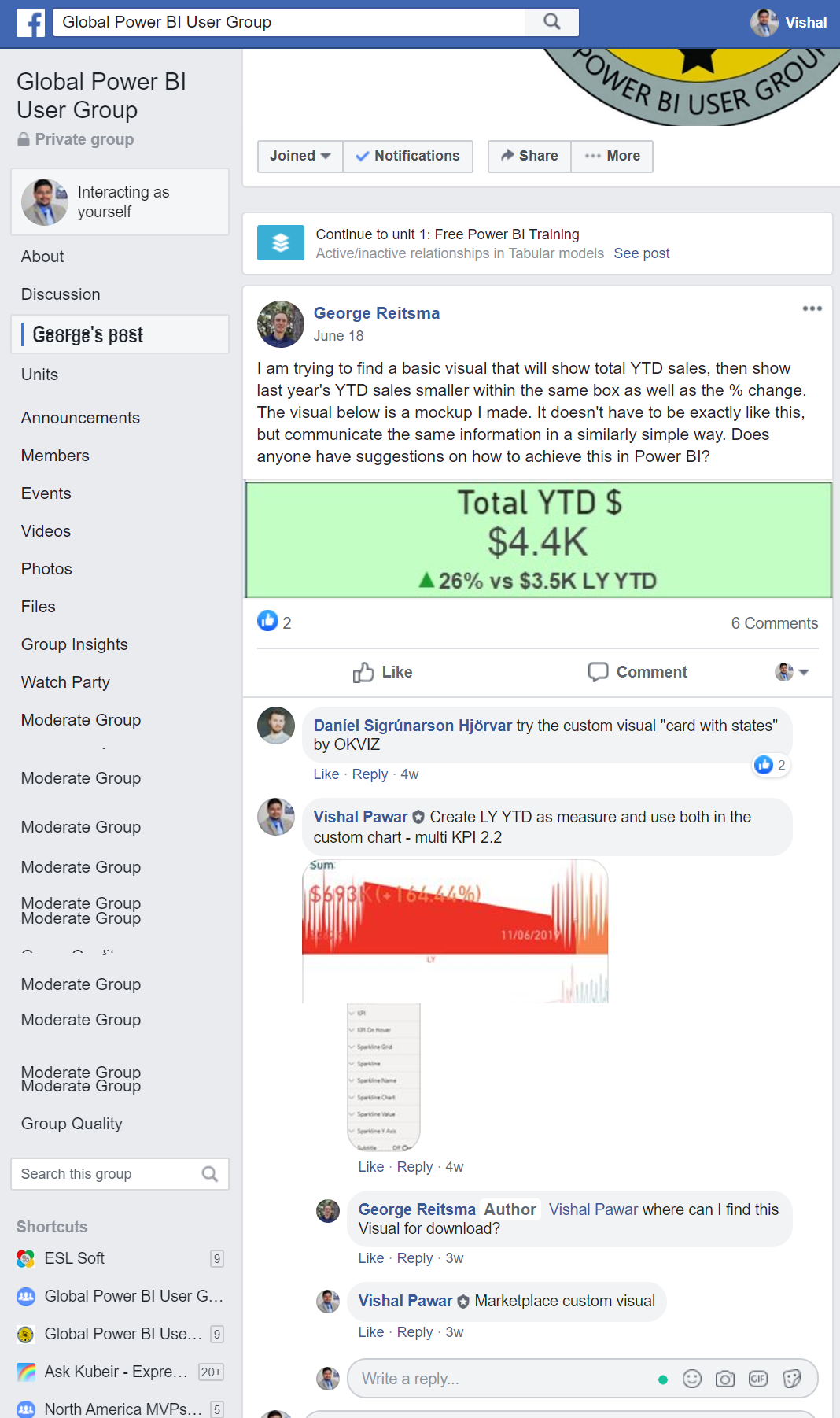
I am trying to find a basic visual that will show total YTD sales, then show last year’s YTD sales smaller within the same box as well as the % change.
The visual below is a mockup I made. It doesn’t have to be exactly like this, but communicate the same information in a similarly simple way. Does anyone have suggestions on how to achieve this in Power BI?